

gooラボリニューアルのお知らせ
2014/12/03
「goo ラボ」、日本語解析技術API を公開
~検索技術の裏側を公開し、オープンイノベーションを加速~
NTT レゾナント株式会社(本社:東京都港区、代表取締役社長:若井 昌宏、以下、NTT レゾナント)は、日本語解析技術に関するAPI を本日より、「goo ラボ」にて公開します。本技術は、NTT 研究所が開発し、長年「goo」にて利用してきたものです。
1.背景
「goo」は、1997 年の提供開始より長年をかけてWeb 検索に関わる技術やノウハウを蓄積し、またNTT 研究所との連携により、世界有数の技術力も有します。一方で、近年、我々の持つWeb 検索技術が、他の自社コンテンツを提供する企業やビッグデータ解析技術を求める企業においても活用が見込まれることから、この度、goo の持つ技術やノウハウを「goo ラボ」にて順次公開することとなりました。
2.公開内容について
第一弾となる今回は、ビッグデータ解析などにおいて必須となる要素技術である「語句類似度算出」「ひらがな化」「固有表現抽出」「形態素解析」の日本語解析API 4 種を公開します。今回公開するAPI の活用により、分析対象となるビックデータが日本語で書かれた文章の場合、単なる文字列の集計だけではなく、より書かれている内容に基いた分析ができるようになります。
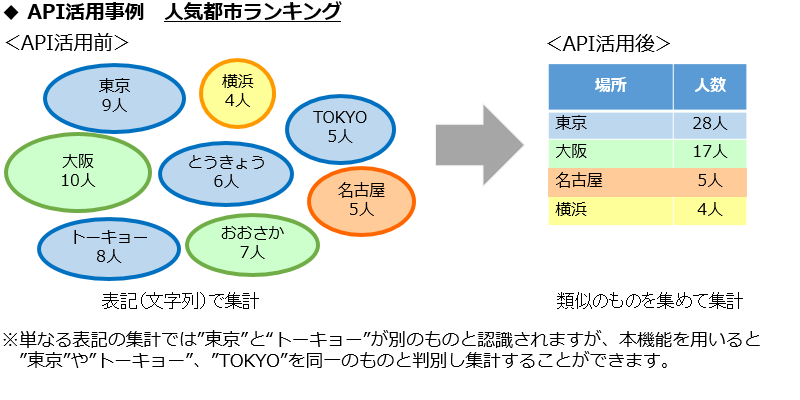
・「語句類似度算出」
2つの語句(キーワード)に対して、構成単語や音素の情報を踏まえて、その類似度合いを算出するAPI になります。
例えば、”トーキョー”と”東京”や、”phablet”と”ファブレット”といった似通った発音を持つ違う表記の語句を、類似度合いにより同じ語句と見なすことができます。このような特徴を持つ語句類似度算出機能により、今まで目視や辞書を使って行っていたデータの統合作業を、自動化することができ、データ分析の精度と生産性を向上させます。
・「固有表現抽出」
トレンドや評判の解析に必須となる人名や地名、組織名などを抽出します。
例えば、”鈴木さんがきょうの9 時30 分に横浜に行きます。”という文字列からは、人名として”鈴木”、地名とし
て”横浜”, 日付表現として”きょう”、時刻表現として”9 時30 分”がそれぞれ抽出されます。抽出されたものを分類し
て集計することにより、SNS 上の投稿のなかで最近話題になっているスポットを発見するといった分析を行うことが
容易になります。
・「ひらがな化」
漢字混じりで書かれた文字列を”ひらがな”もしくは“カタカナ”による記載に変換します。
例えば、”漢字が混ざっている文章”という文字列を、”かんじが まざっている ぶんしょう”と変換します。変換後の文字列は、読みやすいように文中の適当な位置に半角スペースが挿入されるので、子供向けコンテンツの作成などに用いることができます。
・「形態素解析」
日本語の文字列を、形態素と呼ばれる単位に分割します。
例えば”この商品が大好きです”という文字列は、”この”, “商品”, “が”, ”大好き”, ”です”というように分割されます。この解析結果を集計することにより、自社製品のレビュー記事からどのような表現でよく評価されているかといった分析を行うことが容易になります。
3.今後について
今後も、ビッグデータ解析に役立つ技術の公開など、企業や大学などにニーズが高い技術を公開することにより、オープンコラボレーションを加速してまいります。
以上
本件に関する問い合わせ先
NTT レゾナント株式会社 広報担当 立石, 澤田 ☎ 03-6703-6250 pr@nttr.co.jp